服务端反爬?也不过如此!看完小白都能破
发布时间丨2024-10-18 11:00:43作者丨赵小帆浏览丨2112
❝“每日一练,学习分析网站及爬虫开发,从需求>站点>分析>制定方案>编写代码>调试代码>获取数据>验证数据>完成爬虫开发”
一、站点需求梳理
需求如下:
-
网站(只提供分析思路)
-
需要实现两个接口的分析及实现:链接采集接口(简单);搜索采集接口(需要分析下)
-
产品基本信息以及产品的价格,库存数据
-
数据存入kafka数据库中
❝小白分析站点需要学习下,浏览器的控制台调试工具的一些常用的技巧和操作,后面我会专门写一篇浏览器控制台的扫盲文章,帮助小白快速上手浏览器调试分析;。
二、分析站点的结构
❝分析站点我们可以使用浏览器控制台或者使用fiddler等抓包工具,有时候我们还需要对接口模拟请求,可以使用postman等接口测试软件;
-
搜索接口分析
在搜索框中输入查询的关键词:98-98-6,搜索后鼠标右键查看网页源代码,看是否是静态页面;分析会后发现,源代码中并不存在我们的搜索结果.

猜测是异步加载了搜搜结果,进一步在源代码中查看,发现有一段js代码;代码如下:
$(document).ready(function () {
let searchKey = $.trim("98-98-6");
if(searchKey){
let cacheHtml= getItemWithExpiration("search2_"+searchKey.toLowerCase());
if(cacheHtml){
$("#searchHTML").replaceWith(cacheHtml)
}else{
$.ajax({
url: "/product/search.jhtml",
data: {"searchDTO.searchParam":searchKey,"struts.token.name":"_searchToken","_searchToken":$("input[name='_searchToken']").val()},
dataType:"html",
type:"POST",
success:function(html){
setItemWithExpiration(searchKey,html,EXPIRATION_TIME)
$("#searchHTML").replaceWith(html)
}
});
}
}
});
❝代码解释:首先函数接受一个参数,这个参数应该就是我们搜索的关键词;使用getItemWithExpiration()这个函数接受一个参数以search2_+关键词的小写格式,猜测是是获取缓存数据,如果缓存存在则获取缓存中的数据并更新当前页面的搜索结果代码,否则就发送一个ajax请求异步获取数据.到这边我们就确定了我们需要的搜索结果数据来自于这个接口,这个接口method是post,请求的参数三个一个是搜索词,一个固定的字符串,一个是当前页面获取到的搜索token,返回的是html的数据类型. 如果请求成功调用setItemWithExpiration()这个函数保存数据,并将搜索结果替换到源码中.
分析后得出结论:
搜索的列表页面是通过ajax异步加载的,并且需要实时获取搜索页面的token,作为参数发起请求.重新请求并在在控制台获取/product/search.jhtm这个路径的请求并本地编写代码运行.到这边基本的搜索逻辑分析完成.
开始实践验证:
重新在网站的页面进行抓包,F12打开浏览器的控制台,在搜索框中输入查询的关键词:98-98-6,观察控制台的network网络流量包 如下图所示:
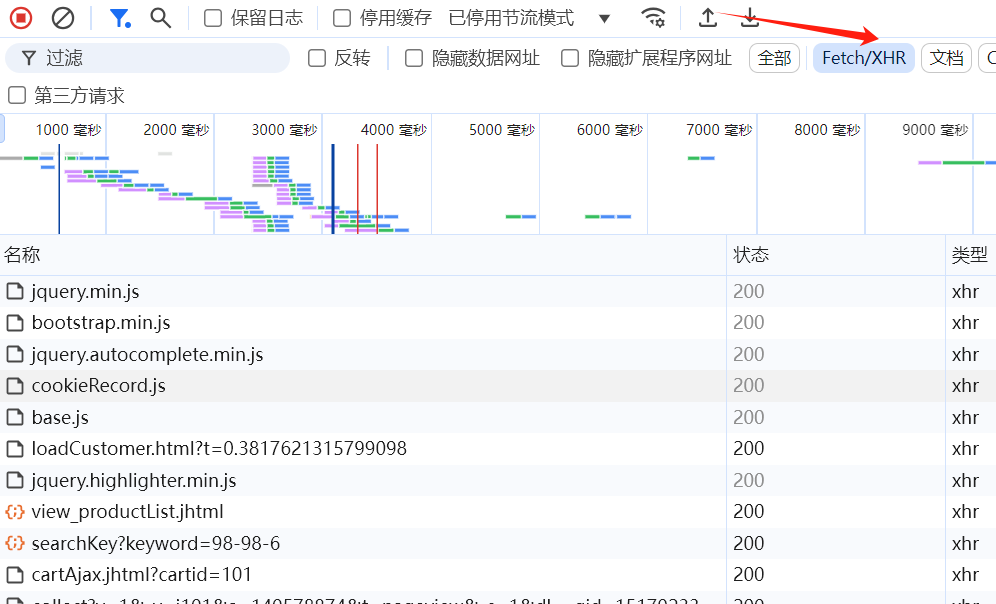 观察数据包并没有发现有我们期望的ajax请求的包,思考中...,明白了上面我们分析异步请求的代码的时候有一个七天的缓存设置,因此我们需要先把缓存清除在发送请求.如下图操作:
观察数据包并没有发现有我们期望的ajax请求的包,思考中...,明白了上面我们分析异步请求的代码的时候有一个七天的缓存设置,因此我们需要先把缓存清除在发送请求.如下图操作:
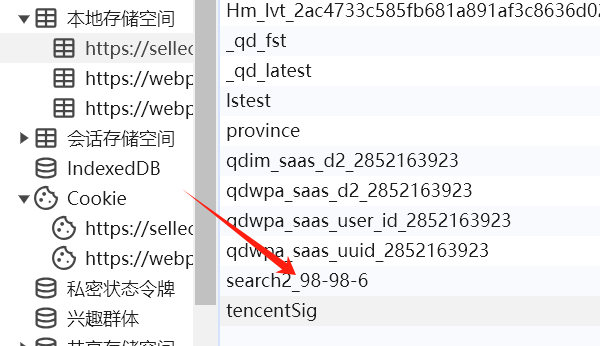
删除之后如下:
重新发送关键词请求
重新发送关键词后在控制台的network中发现出现了我们需要的异步请求路径如下图: 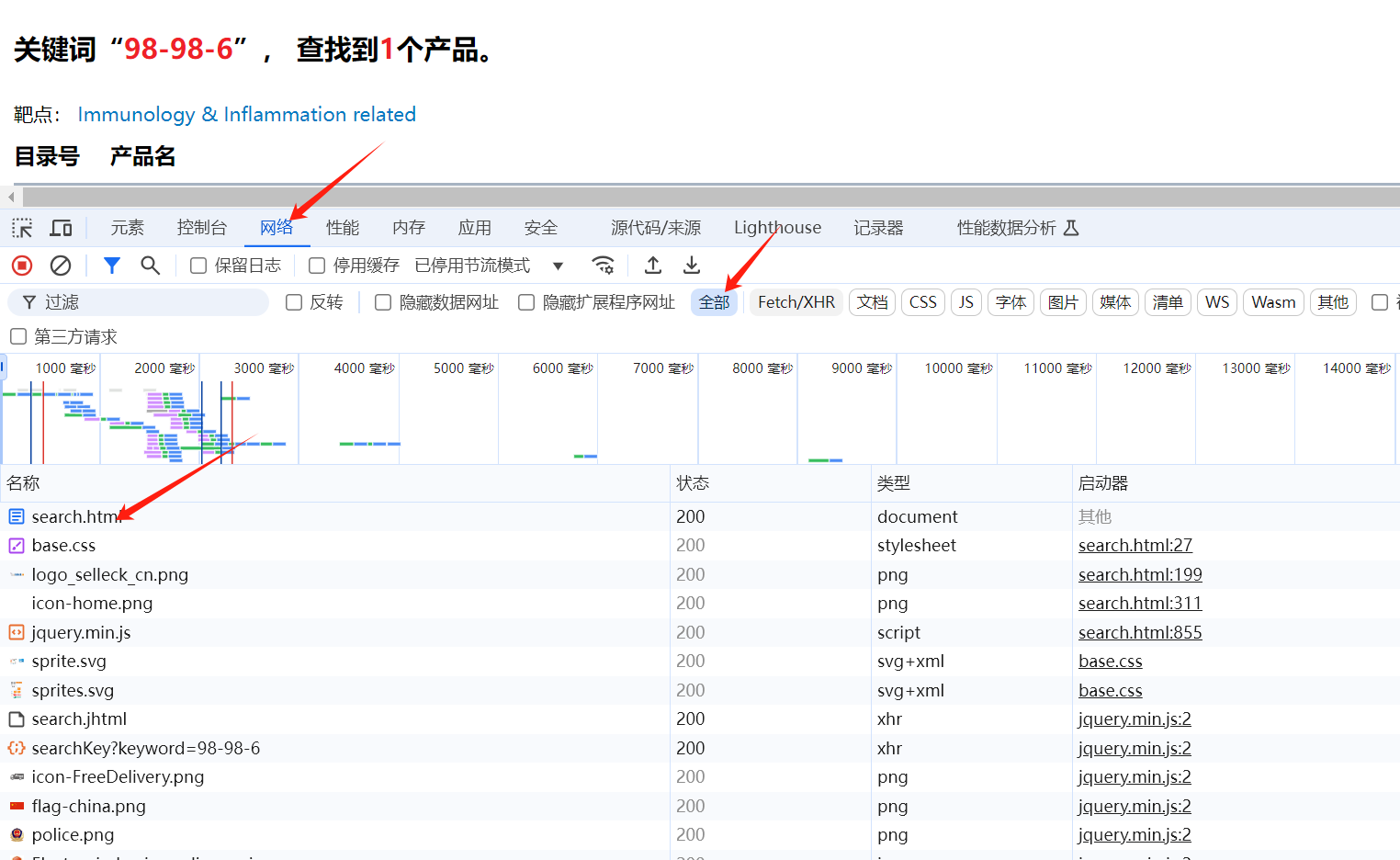
点击进入该路径查看结果如下: 搜索结果页面被完整的渲染出来了 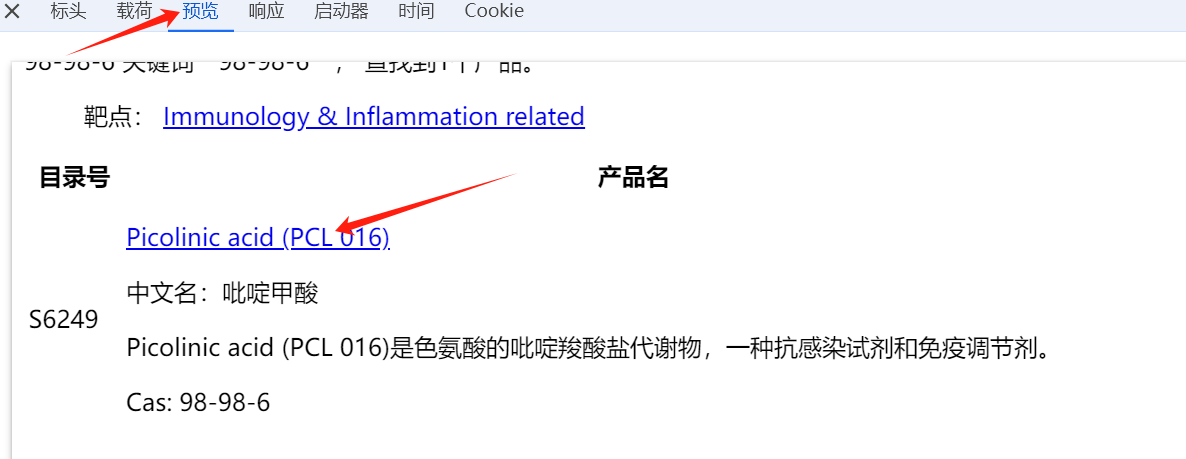
❝链接接口我们暂时不在这边分析,比较简单;搜索接口我们需要分析下数据的参数及参数的获取逻辑.
接口测试
我们根据分析的逻辑第一步请求首页>获取首页的token>请求ajax>参数是搜索关键词以及首页的token.
使用接口测试工具postman对两个接口进行测试:如下: 测试成功!

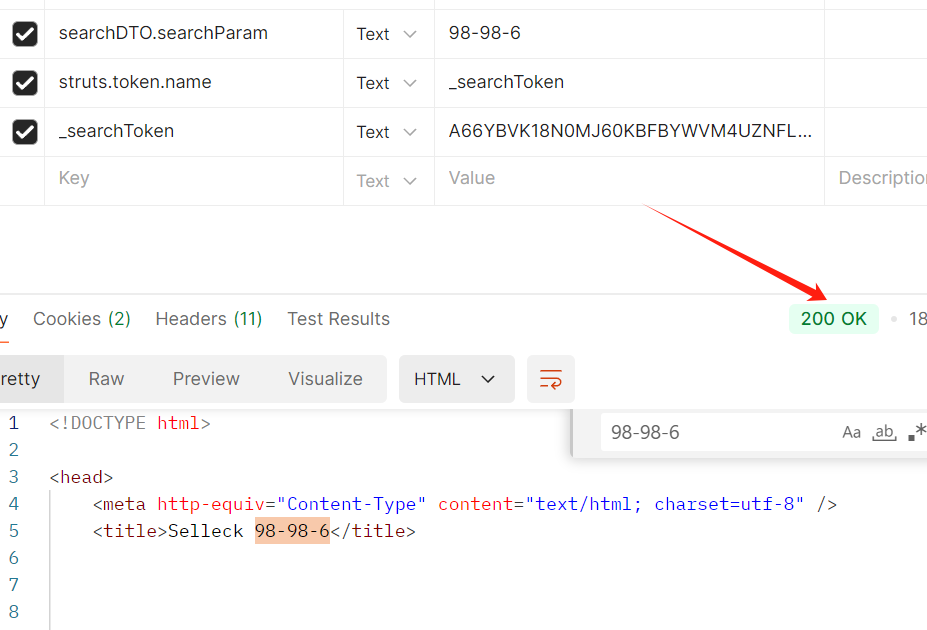
❝测试的时候没有设置任何的headers参数;测试发现每个token只能使用一次;
代码编写
import requests
from parsel import Selector
header={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
payload = {'searchDTO.searchParam': '98-98-6'}
response = requests.post(url, data=payload,verify=False, headers=header)
items = Selector(resp.text)
token = items.css("input[name='_searchToken']::attr('value')").get()
# 请求ajax
data={"searchDTO.searchParam":"98-98-6","struts.token.name":"_searchToken","_searchToken":token}
header={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"}
response = requests.post(url,data=data)
print(response.status_code)
请求结果如下: 发现页面404报错了!

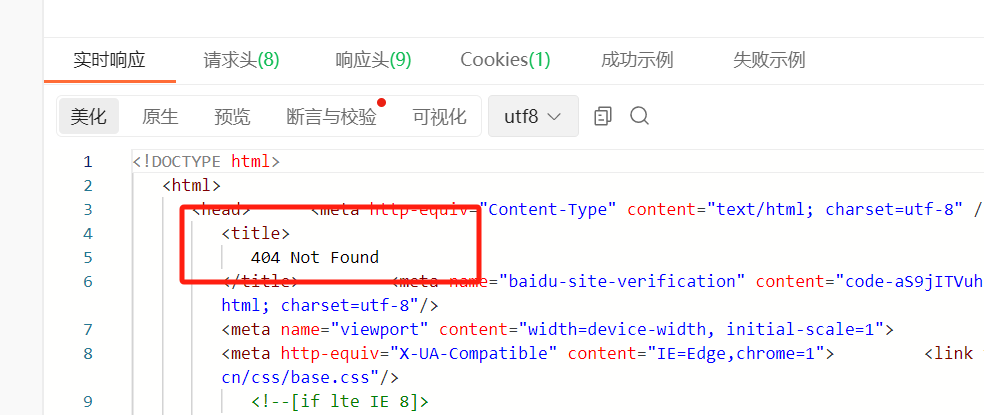
接着分析可能是没有带请求头,把请求头headers的cookie加上之后发现依旧不行. 发现依旧是404!
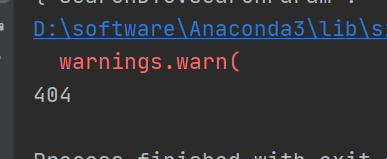
由于我们这边的是需要获取首页的token值作为ajax的参数请求,因此重新换了一个关键词请求并获取他的token.返回结果还是404!观察控制台的网络请求,总共发起了两个请求; 对比自己的代码和postman的代码发现每次请求postman都自动添加了cookie参数为JSESSIONID,因此把这个值添加到了请求中;返现代码返回依旧是404;
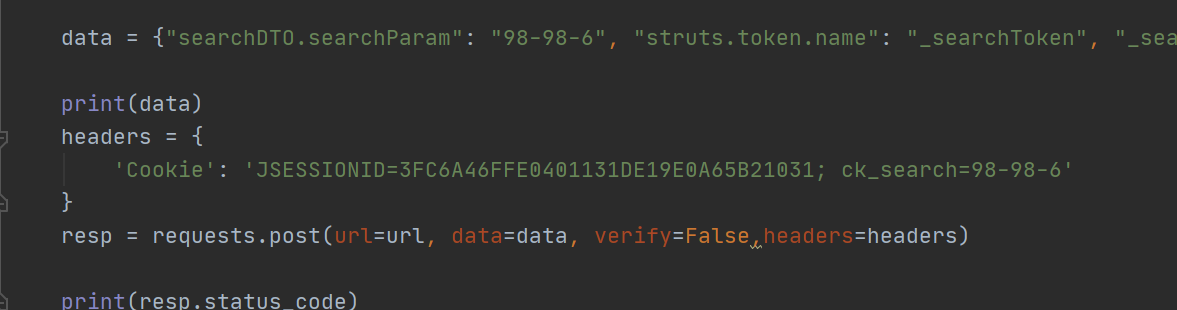
考虑到jsessionid的参数,加上需要先请求首页在获取token,猜测这个cookie有可能需要从上一个接口获取,以此来保存会话。 猜测正确,如下图: 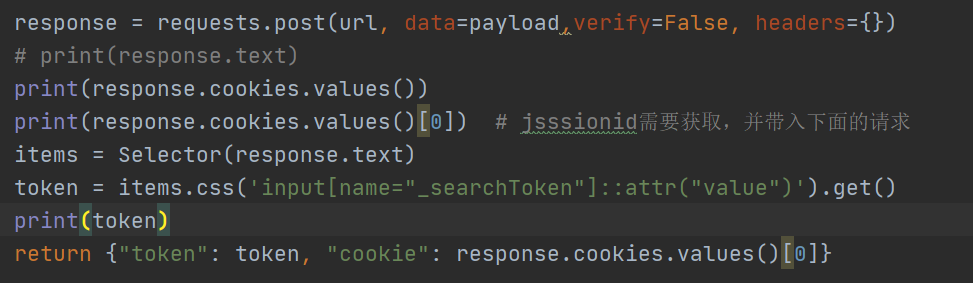
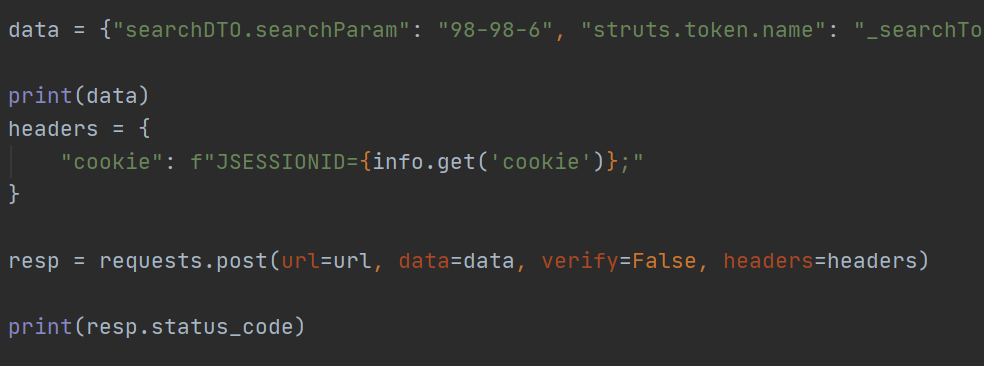
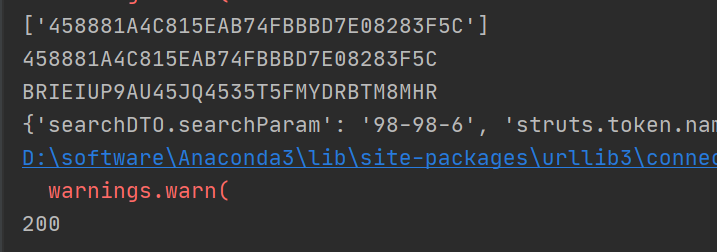
结束语
这个站点的分析到此就完成了,主要分享了站点的搜索接口的参数分析思路。以及测试工具和我们手写代码会存在差异,也是需要主意的地方。
❝需要以上源代码的可以在下面留言:“想要代码”。觉着写的不错的可以帮忙点点赞。并关注公众号:爬虫与大模型开发。
我已经创建了爬虫与大模型开发的星球,非常适合小白入门及爱好爬虫的同学,更多爬虫相关内容我放到了星球,我在星球等同学们来了!
