如何利用pandas解析html的表格数据
发布时间丨2024-05-13 15:33:21作者丨zhaomeng浏览丨7
我们在编写爬虫的过程中,经常使用的就是parsel、bs4、pyquery等解析库。在博主的工作中经常的需要解析表格形式的html页面,常规的写法是,解析table表格th作为表头,解析td标签作为表格的行数据 。循环tr标签生成一个列表,在与th做映射整理称字典的格式,存入list中。那么有一种更为方便的方法就是使用pandas 只需要一行代码就可以完成常见表格的编写。案例如下:
我们现在使用pandas获取这个链接的table信息
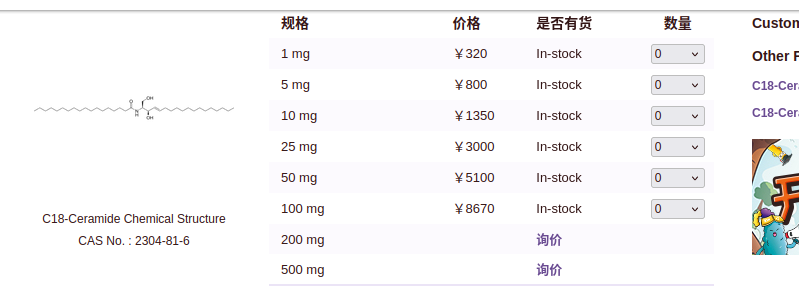
代码如下:
import pandas as pd
import requests
resp = requests.get("https://www.medchemexpress.cn/c18-ceramide.html")
response = resp.text
info = pd.read_html(response,attrs={"id":"con_one_1"})
print(info)
for inf in info:
print(inf.values)
运行结果如下:表格数据直接就被解析成一个二元列表,每一个列表就是一个tr标签 每个列表值就是一个td.
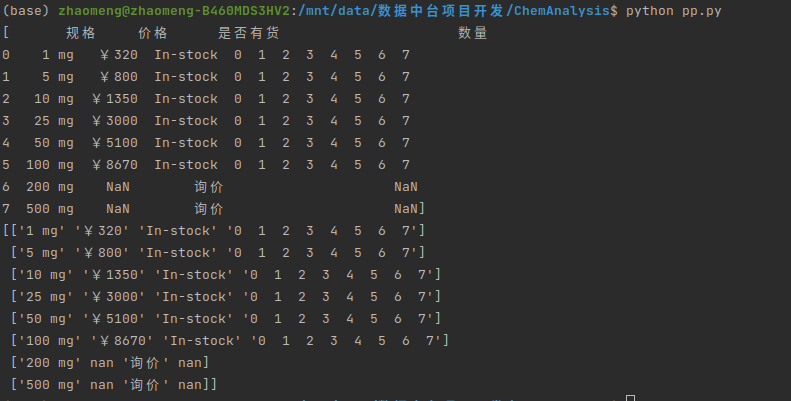
只需要指定html文件以及指定页面的table;attrs={}用来定位解析的table数据这边是id="con_one_1"的table;
只需要for循环就可以转换成字典了;
今天的分享pandas解析table;
喜欢我的文章可以关注我
