gerapy部署定时任务采集资讯数据
发布时间丨2022-05-30 09:55:16作者丨zhaomeng浏览丨2
由于业务需求,为丰富网站的资讯内容,选择了几个更新频率比较高的网站做定时任务的采集,这样的采集需求在日常的资讯新闻上面是比较多的,由于我们需要经常的发布一些行业资讯,但是人工作方式显然不能满足一个大的数据平台的需求量,因此我们需要寻找很多的行业相关的资讯平台网站,这类网站需要具有高度行业相关性及更新频率需要高,最好是日更新多篇的频率.这样我们用爬虫 的思维去监控定时采集网站的资讯信息,并且以转载的形式使用这类文章.同时需要对文章的内容做处理,去除一些比较敏感的关键词,去除超链接的链接,防止不必要的 外链跳转,影响平台的seo优化及用户体验.本次记录分享资讯采集到内容处理及项目部署及定时任务的全过程!
- 分析目标站点,包括分析网站的页面结构,文章内容及响应方式便于我们掌握制定采集的方案.
- 网站内容的更新频率,以便于我们确定该网站是否具有定时采集的价值,
- 网站的相关性,有专业岗位对网站的资讯进行分类,便于我们对网站的内容进行分类存储.
- 分析网站的文本内容,对网站 的相关敏感词及链接的特征进行标记,便于具体的做一些数据清洗.
- 分析页面的图片信息,便于我们对采集图片作出一定的处理,对图片的链接及图片的展示形式,图片的编码压缩作出分析处理.
爬虫部署的开源的框架gerapy,相信做爬虫的绝大部分的人都知道并基本都使用过他,用起来还是很不错的,对爬虫的部署提供了可视化的界面及对维护爬虫起到了很好的帮助!
部署部分大家基本上都熟悉的,不了解的朋友可以到gethub了解学习下,就不再赘述了。直接来说定时任务的部署,如下图定时任务的部署界面。

以此填写项目的备注名、爬虫的项目名称、爬虫的名称、选择部署的主机(资讯采集、sciencenet、science)
调度的方式选择的有三种:
- date:以指定的日期运行定时任务
- interval:以间隔的时间运行定时任务
- crontab:以linux的方式运行定时任务
第一种date方式如下:
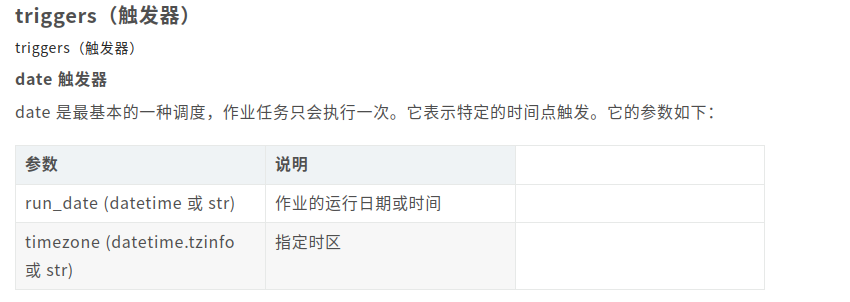
# date 触发器使用示例如下:
from datetime import datetime
from datetime import date
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print(text)
scheduler = BackgroundScheduler()
# 在 2017-12-13 时刻运行一次 job_func 方法
scheduler .add_job(job_func, 'date', run_date=date(2017, 12, 13), args=['text'])
# 在 2017-12-13 14:00:00 时刻运行一次 job_func 方法
scheduler .add_job(job_func, 'date', run_date=datetime(2017, 12, 13, 14, 0, 0), args=['text'])
# 在 2017-12-13 14:00:01 时刻运行一次 job_func 方法
scheduler .add_job(job_func, 'date', run_date='2017-12-13 14:00:01', args=['text'])
scheduler.start()
第二种interval方式如下:

代码示例:
#interval 触发器使用示例如下:
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
# 每隔两分钟执行一次 job_func 方法
scheduler .add_job(job_func, 'interval', minutes=2)
# 在 2017-12-13 14:00:01 ~ 2017-12-13 14:00:10 之间, 每隔两分钟执行一次 job_func 方法
scheduler .add_job(job_func, 'interval', minutes=2, start_date='2017-12-13 14:00:01' , end_date='2017-12-13 14:00:10')
scheduler.start()
第三种crontab方法如下:
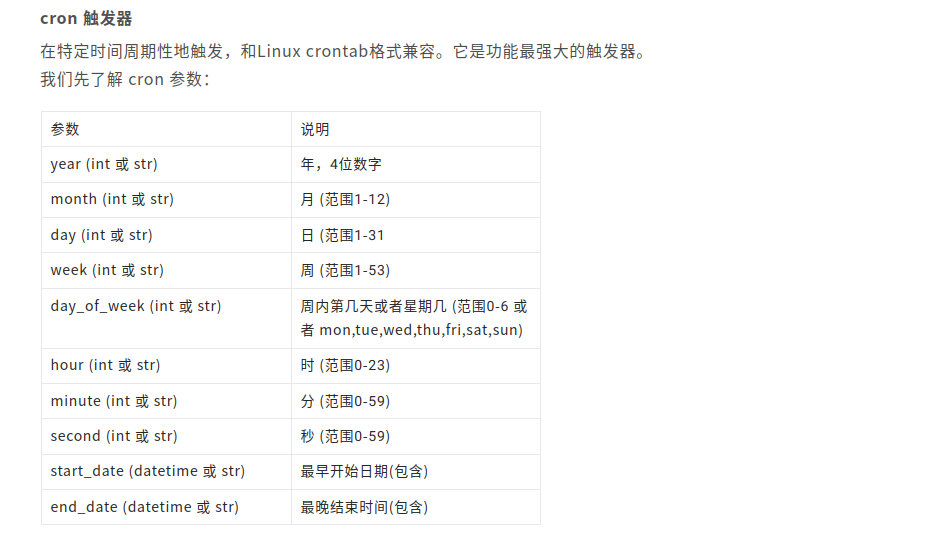
crontab示例代码如下:
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
# 在每年 1-3、7-9 月份中的每个星期一、二中的 00:00, 01:00, 02:00 和 03:00 执行 job_func 任务
scheduler .add_job(job_func, 'cron', month='1-3,7-9',day='0, tue', hour='0-3')
scheduler.start()
这里以第三种的方式运行,任务设置为每年每月每周的周一到周五的中午12点及晚上18点运行
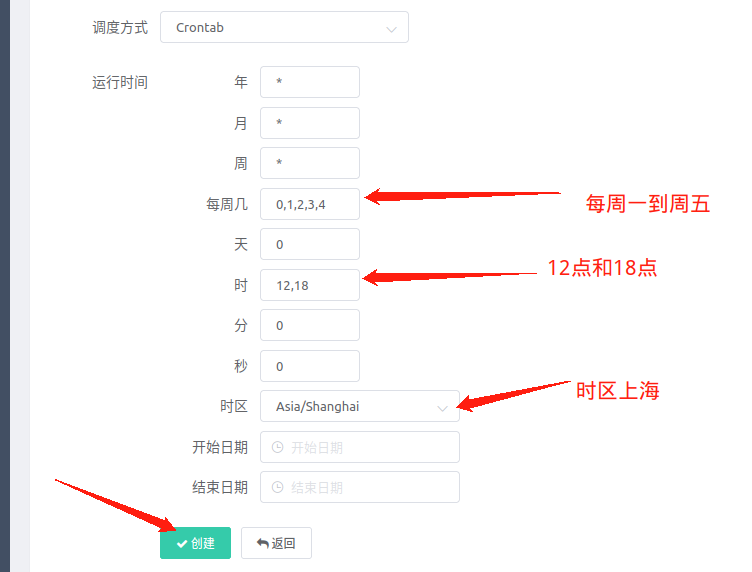
这样就创建完成了!
会出现的问题是:如果gerapy重启了那么这个定时任务就需要将任务删除,同时进入后台将执行的任务全部删除,再回到前台重新部署!切忌!