Scrapy对接Selenium
发布时间丨2021-11-08 10:53:39作者丨zhaomeng浏览丨109
在我们的爬虫中会遇到异步的爬虫我们可以通过抓包获取接口直接请求获取数据。也会遇到纯JS加载的数据网站,这里我们就需要使用自动化测试工具来模拟浏览器的运行将数据通过浏览器渲染出来获取。因此,可以看出模拟浏览器的功能用到爬虫开发上是非常有效的。可以帮助我们像获取普通网站的数据那样直接获取到我们想要的数据。但是他也有他的缺点就是运行的效率比较低,因为他在模拟浏览器的时候是加载了整个网站的资源,例如文件、图片、流媒体等。现在的反爬虫也会针对自动化测试工具进行参数的检测用于阻止它的运行。这个情况我会在后面的博文中进行分析。本片博文记录的是我用scrapy+selenium进行爬虫开发的实际项目。
第一步:首先我们需要安装selenium,方式有两种,一种是本机安装但是只能使用在本地,另一种是使用docker安装selenium的情况,也是本片博文的主要介绍。
1、docker 安装selenium使用如下步骤:
docker search [image] 查看镜像是否存在
docker search selenium/standalone-chrome
docker pull [image] 拉取下载镜像
docker pull selenium/standalone-chrome
docker run 创建容器
docker run -d -p 49154:4444 --shm-size=2g -e TZ=Asia/Shanghai selenium/standalone-chrome
--shm-size=2g设置缓存为2g, TZ设置时间为Asia/Shanghai
到这里selenium使用docker安装完成
第二步:验证selenium
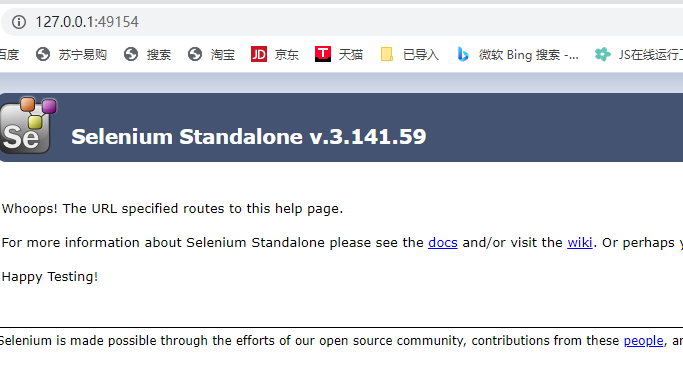
1、浏览器输入127.0.0.1:49154出现下面的图片代表安装成功:
2、也可以使用代码来验证是否安装成功,也就是是否能够渲染网站并返回正确的数据:
from selenium import webdriver
browser = webdriver.Remote(
command_executor="http://192.168.1.180:49154/wd/hub",
desired_capabilities=DesiredCapabilities.CHROME
)
browser.get(url)
print(browser.page_source)
第三步:对接scrapy框架
1、这里我使用的是对接的下载中间件的方式,设置浏览器的所有权限:代码如下:
# 以最高权限运行
options.add_argument('--no-sandbox')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
print(len(request.url))
print(request.url)
global browser
try:
if len(request.url) < 50:
browser = webdriver.Remote(
command_executor="http://127.0.0.1:49154/wd/hub",
desired_capabilities=DesiredCapabilities.CHROME
)
browser.get(request.url)
except WebDriverException:
logging.info("数据不存在,链接超时")
else:
return HtmlResponse(url=request.url, encoding='utf-8', body=browser.page_source, request=request)
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
常见的selenium设置属性如下:
option = webdriver.ChromeOptions()
# 添加UA
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"')
# 指定浏览器分辨率
options.add_argument('window-size=1920x3000')
# 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 以最高权限运行
options.add_argument('--no-sandbox')
# 手动指定使用的浏览器位置
options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
#添加crx插件
option.add_extension('绝对路径')
# 禁用JavaScript
option.add_argument("--disable-javascript")
# 设置开发者模式启动,该模式下webdriver属性为正常值
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values' : {
'notifications' : 2
}
}
options.add_experimental_option('prefs',prefs)
driver=webdriver.Chrome(chrome_options=chrome_options)
每次爬虫的请求都会从这个下载中间件的地方通过,并获取数据返回给爬虫解析。
2、在配置文件中需要启动下载中间件如下:
DOWNLOADER_MIDDLEWARES = {
'ambeed.middlewares.AmbeedDownloaderMiddleware': 544,
}
这样scrapy+selenium的对接配置就完成了!
文章属于原创,转载请注明出处!